
You can't improve what you don't measure. — often attributed to Peter Drucker
In this first article of our series, we share research and testing results to answer a key question: Can large language models help improve automated security testing?
We benchmarked leading AI models on a classic web vulnerability: Cross-Site Scripting (XSS). Tests covered five levels of difficulty, from basic reflected XSS to complex DOM manipulation that triggers JavaScript execution.
Why Evaluate
Evaluations (or evals) are essential for any AI agent system. They measure how well a system performs a task and help answer questions like:
- "How good is my agent at this task?"
- "Will a new tool improve or reduce my agent's performance?"
Without a structured eval, model upgrades, prompt changes, and tooling decisions become guesswork. Evals turn intuition into measurement.
Methodology
We conducted the benchmark using the XSS Game challenge, which has five levels of increasing difficulty for detecting XSS vulnerabilities. Each model was tested on all levels, and we collected the following metrics:
- Vulnerability Detection Rate — percentage of tests where vulnerabilities were correctly identified
- Token Usage — total and average tokens used per test (input + output)
- Task Duration — time taken to complete each test
- Tool Calls — number of tool invocations (HTTP requests) made during testing
Our agents used a customized version of the ReAct pattern to structure their reasoning and approach.
Models tested:
| Model | Provider | Tier |
|---|---|---|
| Claude Sonnet | Anthropic | Frontier |
| Claude Haiku | Anthropic | Efficient |
| GPT-5.1 | OpenAI | Frontier |
| GPT-5-mini | OpenAI | Efficient |
| GPT-5-nano | OpenAI | Nano |
| Gemini Pro | Frontier | |
| Gemini Flash | Efficient |
Results
Vulnerability Detection Rate
The vulnerability detection rate measures the percentage of tests in which the agent successfully identified XSS vulnerabilities. This metric directly reflects an agent's effectiveness in real-world security testing scenarios.
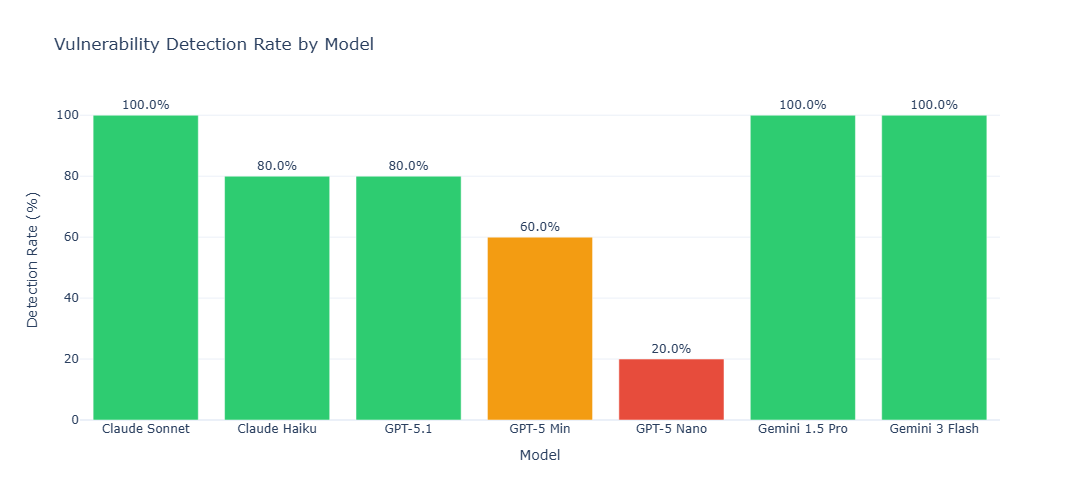
- Both Gemini Pro, Flash, and Claude Sonnet achieved 100% accuracy, closely followed by GPT-5.1 and Claude Haiku.
- Smaller OpenAI models such as GPT-5-mini (60%) and GPT-5-nano (20%) showed lower accuracy.
This demonstrates a clear tradeoff between performance and resource usage, highlighting which models are suitable for large-scale automated testing.
Cost Analysis: Token Usage
Token usage directly impacts API costs. We measured both total token consumption across all tests and average tokens per test to identify the most cost-effective model for security testing.
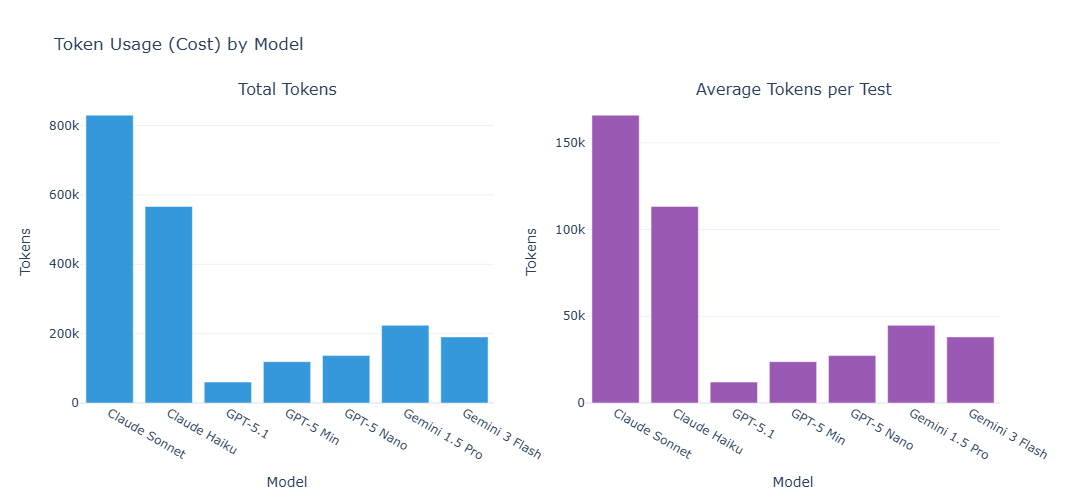
Gemini variants offered the best balance of performance and cost, forming the Pareto frontier for efficiency. Anthropic models, such as Sonnet, were roughly 6× more expensive per sample than Gemini models while delivering similar detection performance.
Task Duration
Task duration measures the time an agent takes to complete each test. Faster models allow more comprehensive testing within tight schedules, increasing overall assessment throughput.
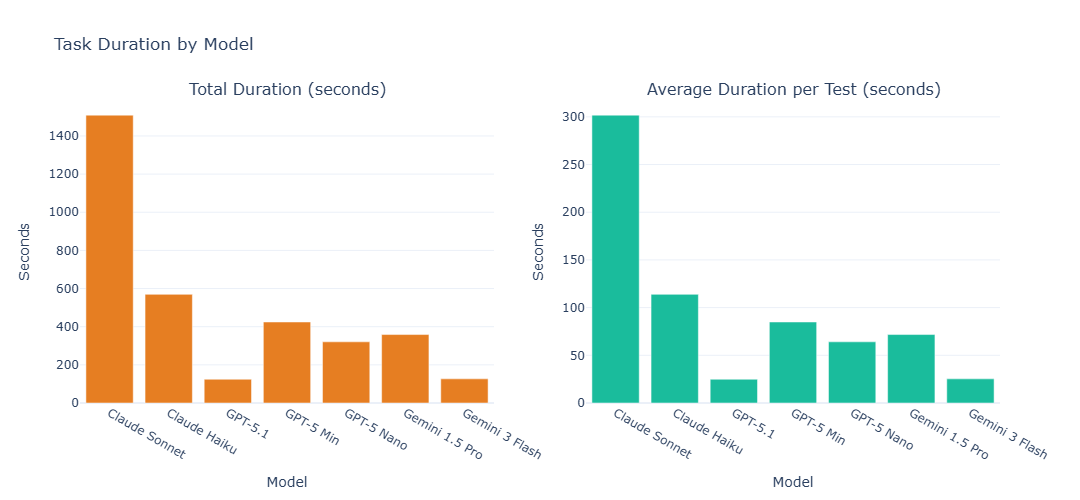
As expected, smaller (or rather cheaper) models typically had lower request latency and general wall-clock task duration than their larger model family counterparts — but Gemini Flash's combination of speed and accuracy stood out. Gemini Flash completed tasks the fastest at ~160s average. It achieved this while also clocking fewer tool calls per run (see Tool Efficiency section below).
Tool Call Efficiency
Tool calls represent the agent's interactions with testing tools (e.g., HTTP requests). Fewer tool calls may indicate more efficient reasoning, while more tool calls might suggest thorough exploration of attack vectors.
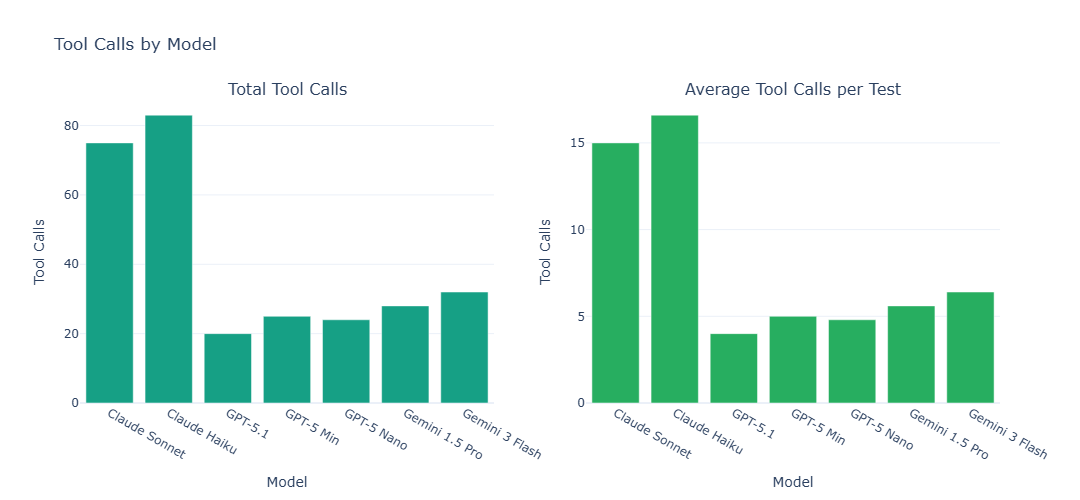
Claude variants averaged ~15 tool calls per test, whereas Gemini variants averaged only ~6. This demonstrates that Gemini agents can achieve high precision while minimizing unnecessary tool usage, saving both time and resources.
Accuracy vs. Cost Tradeoff
This analysis compares accuracy (vulnerability detection rate) with cost (average tokens per test) to help teams select the optimal model based on budget and performance needs.
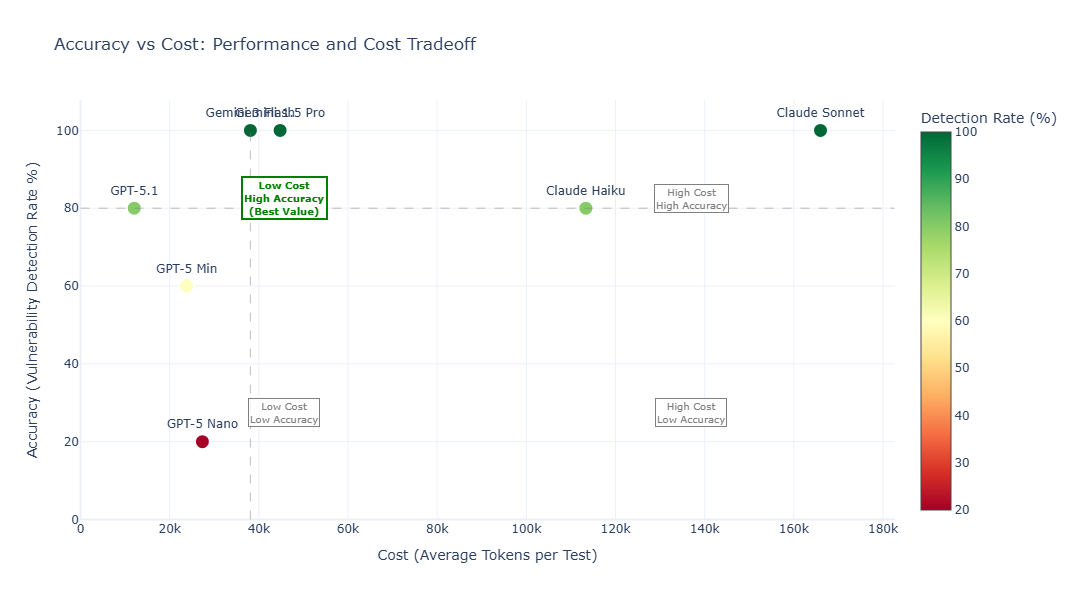
- Models in the upper-left quadrant, such as Gemini variants and GPT-5.1, offer the best value — combining high accuracy with low cost.
- Claude models achieve high accuracy but at a significantly higher cost.
Tool Calls vs. Accuracy Tradeoff
This chart illustrates the relationship between tool call efficiency and accuracy. This metric is important for understanding how effectively each model reasons and plans its testing strategy — fewer tool calls often indicate better problem-solving capabilities and more strategic thinking.
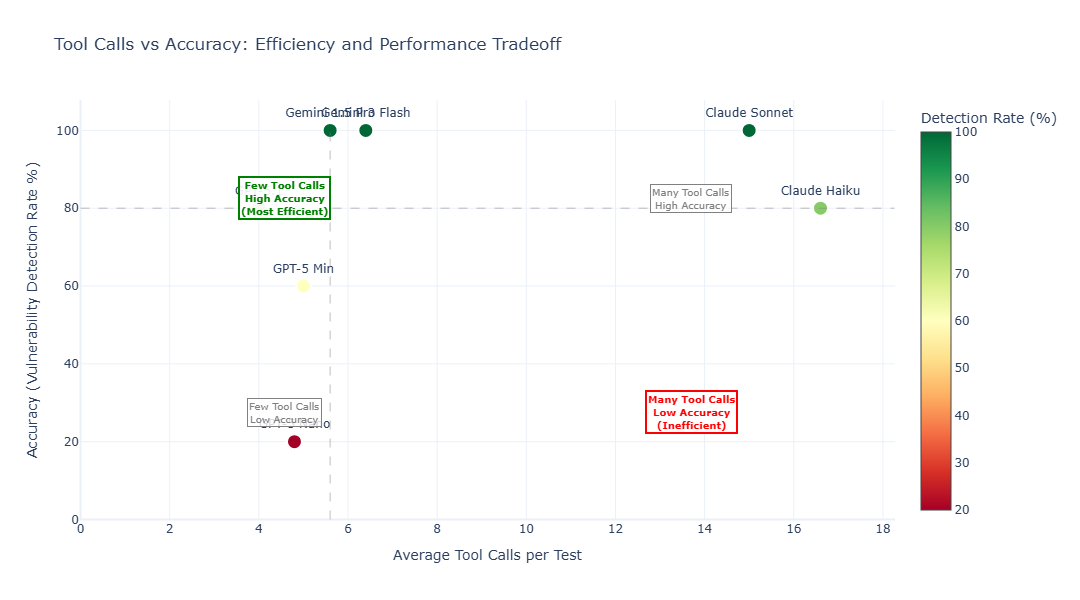
Models with high accuracy and few tool calls — like GPT-5.1 and Gemini variants — are the most efficient, solving tasks with minimal tool interactions. Anthropic models required more tool calls to achieve similar accuracy, indicating less efficient task planning.
Conclusion
Our tests show clear differences between models depending on what matters most.
- For pure detection performance: Claude Sonnet and Gemini Pro/Flash reached the top with a 100% detection rate.
- For efficiency: Gemini Flash used the fewest resources, averaging about 40K tokens per test. It was also the fastest model, completing tests in about 24 seconds on average.
These results show that the best model depends on your priority: maximum accuracy, lowest cost, or highest speed. They also confirm that modern AI agents can already handle complex vulnerability testing tasks in a reliable and measurable way.
Early Access — Try What We Built
We turned these insights into a platform designed to remove the limits of traditional security testing. It uses optimized agents, fast execution, and smart resource use to deliver accurate results in a fraction of the time.
Join our waiting list to be among the first companies to test it and see how automated AI testing can simplify your security workflow while saving time and cost.

Hypersec Research Team
Information Security Research